RECENTLY READ
UPCOMING READING
U-Net Convolutional Networks for Biomedical Image Segmentation
Jan 3, 2021 DL segmentation med. images
Table of Contents
Summarize
The U-Net is a Convolutional network consisting of two paths, called contracting and expanding path. This network was developed for the use of medical image segmentation. It learns fast and does not need a lot of images to perform better then the state-of-the-art networks of this time. It heavily used data augmentation to artificially increase the number of available images.
This network won the EM segmentation challange at ISBI 2012 by a large margin.
Network
The network consisting of the two paths (contracting and expanding) is build on the architecture called “fully convolutional network”.
The network architecture is illustrated in Figure 1. It consists of a contracting path (left side) and an expansive path (right side). The contracting path follows the typical architecture of a convolutional network. It consists of the repeated application of two 3x3 convolutions (unpadded convolutions), each followed by a rectified linear unit (ReLU) and a 2x2 max pooling operation with stride 2 for downsampling. At each downsampling step we double the number of feature channels. Every step in the expansive path consists of an upsampling of the feature map followed by a 2x2 convolution (“up-convolution”) that halves the number of feature channels, a concatenation with the correspondingly cropped feature map from the contracting path, and two 3x3 convolutions, each fol- lowed by a ReLU. The cropping is necessary due to the loss of border pixels in every convolution. At the final layer a 1x1 convolution is used to map each 64- component feature vector to the desired number of classes. In total the network has 23 convolutional layers. To allow a seamless tiling of the output segmentation map (see Figure 2), it is important to select the input tile size such that all 2x2 max-pooling operations are applied to a layer with an even x- and y-size.
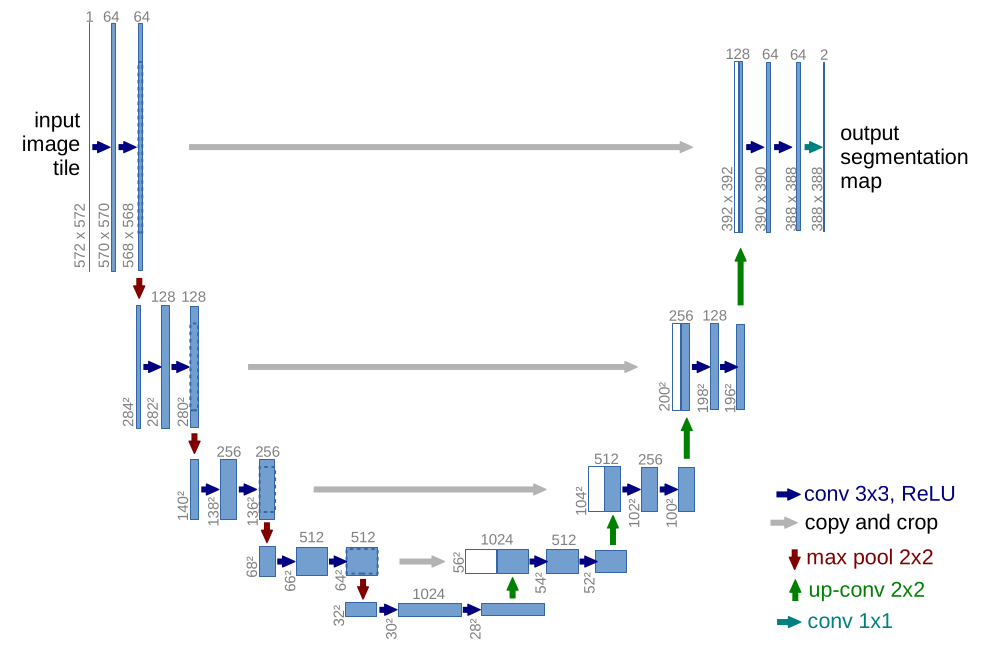 U-net architecture (example for 32x32 pixels in the lowest resolution).
Each blue box corresponds to a multi-channel feature map.
The number of channels is denoted on top of the box. The x-y-size is provided at the lower
left edge of the box. White boxes represent copied feature maps.
The arrows denote the different operations.
U-net architecture (example for 32x32 pixels in the lowest resolution).
Each blue box corresponds to a multi-channel feature map.
The number of channels is denoted on top of the box. The x-y-size is provided at the lower
left edge of the box. White boxes represent copied feature maps.
The arrows denote the different operations.
With the used convolution a padding is used, by mirroring the pixels at the boarder.
Data augmentation
In the field of medical images the available data is mostly limited. That is why the network benefits from using data augmentation to increase the training set.
Metadata:
| Author: | Olaf Ronneberger, Philipp Fischer, and Thomas Brox |
| Released: | May 18, 2015 |
| Source: | Link |