RECENTLY READ
UPCOMING READING
ImageNet Classification with Deep ConvolutionalNeural Networks
Jan 3, 2021 DL classification images
Table of Contents
Summary
Alex Krizhevsky et al. created a deep convolutional neural network, that outperformed other methods of image classification from the ImageNet LSVRC-2010 contest. With a modified variant with this model they entered the ILSVRC-2012 competition and won by a significant margin.
The network classified 1.2 million images with 1000 different classes.

The architecture was a simple network compared to network from today (2021). It was one of the first CNNs that showed the potential of this structure for image recognition. Additionally Krizhevsky presented some newer ideas in regards to neural network, like ReLu and parallel training.
Network
Structure
The network consisted of five convolutional layers followed by three fully-connected layers. This depth achieved the best result with the given hardware limitation, what was the main factor for the size. Smaller network achieved worse performance: “we found that removing any convolutional layer (each of which contains no more than 1% of the model’s parameters) resulted in inferior performance.”
To this day most network used the than(x) function as activation function.
With the use of ReLU (Rectified Linear Units) max(x,0) the network was able to learn much faster.
Local Response Normalization was used after some of the ReLU layers.
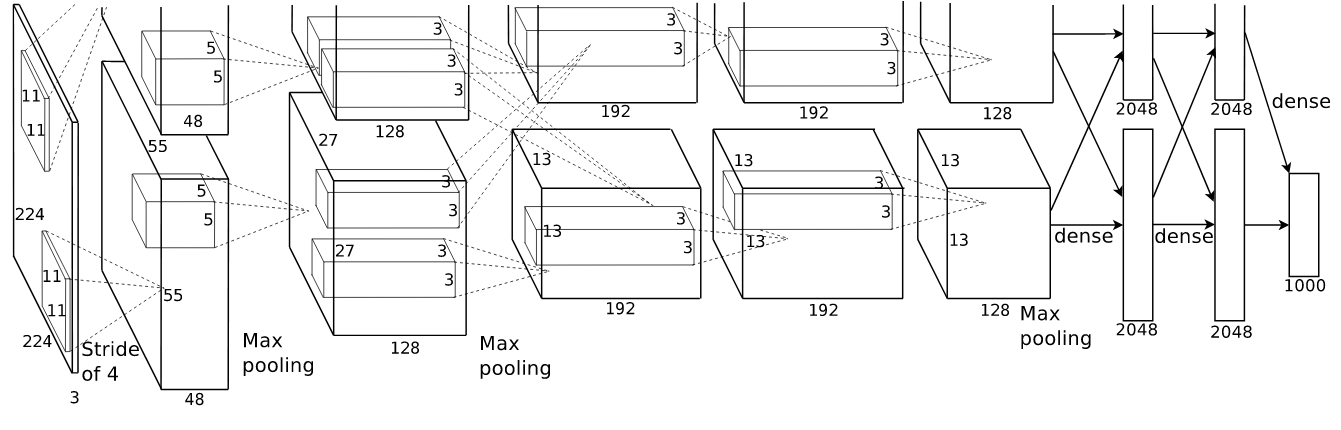 An illustration of the architecture of our CNN, explicitly showing the
delineation of responsibilities between the two GPUs. One GPU runs the layer-parts
at the top of the figure while the other runs the layer-partsat the bottom.
The GPUs communicate only at certain layers. The network’s input is 150,528-dimensional,
and the number of neurons in the network’s remaining layers is given by
253,440–186,624–64,896–64,896–43,264–4096–4096–1000.
An illustration of the architecture of our CNN, explicitly showing the
delineation of responsibilities between the two GPUs. One GPU runs the layer-parts
at the top of the figure while the other runs the layer-partsat the bottom.
The GPUs communicate only at certain layers. The network’s input is 150,528-dimensional,
and the number of neurons in the network’s remaining layers is given by
253,440–186,624–64,896–64,896–43,264–4096–4096–1000.
Preventing Overfitting
Data Augmentation
As stated from the authors: “The easiest and most common method to reduce overfitting on image data is to artificially enlarge the dataset using label-preserving transformations”
To create artificial images the authors translated and reflected horizontally the images. The second data augementation was to alter the intensity of the RGB values.
Dropout
To further reduce the possibility of overfitting, a dropout was used to prevent some of the neurons to train during a step.
Metadata:
| Author: | Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton |
| Released: | Dec 1, 2012 |
| Source: | Link |